移动机器人全局路径规划算法Dijkstra,A*知识整理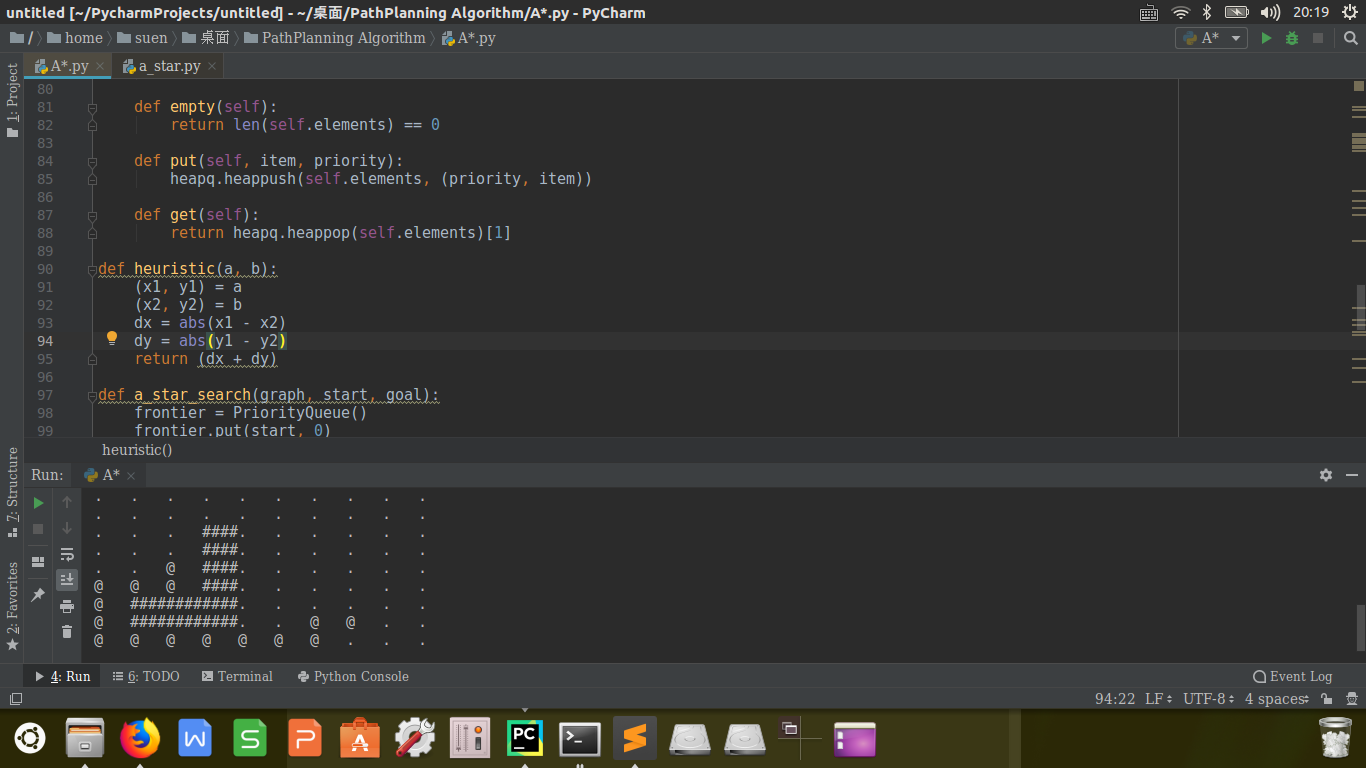
修养的花儿在寂静中开过去了,
成功的果子便要在光明里结实。
路径规划是指的是机器人的最优路径规划问题,即依据某个或某些优化准则(如工作代价最小、行走路径最短、行走时间最短等),在工作空间中找到一个从起始状态到目标状态能避开障碍物的最优路径。也就是说,路径规划应注意以下三点:
- 明确起点与终点
- 避开障碍物
- 路径上的优化
算法介绍
A*算法和Dijkstra算法都是基于图的优化搜索算法,以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。作为Dijkstra算法的优化扩展,A_star算法同时考虑了当前点到起始点以及目标点的距离因素,节省了扩散点的范围,因其高效性而被广泛应用于寻路及图的遍历。
算法原理
通过Dijkstra计算图G中的最短路径时,需要指定起点s(即从顶点s开始计算)。此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点s的距离)。
初始时,S中只有起点s;U中是除s之外的顶点,并且U中顶点的路径是”起点s到该顶点的路径”。然后,从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 然后,再从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 … 重复该操作,直到遍历完所有顶点。
A*算法则是在评价函数上考虑到了“该顶点到目标点的估计路径”,将该点到目标点的及起始点的路径成本之和作为评价最终路径的指标,大大缩小了遍历点的个数,提高了算法效率。
算法术语
搜索区域(The Search Area)
图中的搜索区域被划分为了简单的二维数组,数组每个元素对应一个小方格,当然我们也可以将区域等分成是五角星,矩形等,通常将一个单位的中心点称之为搜索区域节点(Node),而非方格(Squares)。
开放列表(Open List)
我们将路径规划过程中待检测的节点存放于Open List中,而已检测过的格子则存放于Close List中。
父节点(parent)
在路径规划中用于回溯的节点,开发时可考虑为双向链表结构中的父结点指针。
路径排序(Path Sorting)
启发式函数由以下公式确定:F(n) = G(n) + H(n)G代表的是从初始位置A沿着已生成的路径到当前点的成本值。H指当前点到目标节点B的估计成本值。
启发函数(Heuristics Function)
H为启发函数,也被认为是一种试探,由于在找到唯一路径前,我们不确定在前面会出现什么障碍物,因此用了一种计算H的算法,具体根据实际场景决定。在我们简化的模型中,H采用的是传统的曼哈顿距离(Manhattan Distance),也就是横纵向走的距离之和。
算法流程
建立栅格地图
建立栅格地图,设置边(障碍物)权重,初始化起点与目标点,代码封装如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def draw_grid(graph, width=2, **style):
for y in range(graph.height):
for x in range(graph.width):
print("%%-%ds" % width % draw_tile(graph, (x, y), style, width), end="")
print()
class GridWithWeights(SquareGrid):
def __init__(self, width, height):
super().__init__(width, height)
self.weights = {}
def cost(self, from_node, to_node):
return self.weights.get(to_node, 1)
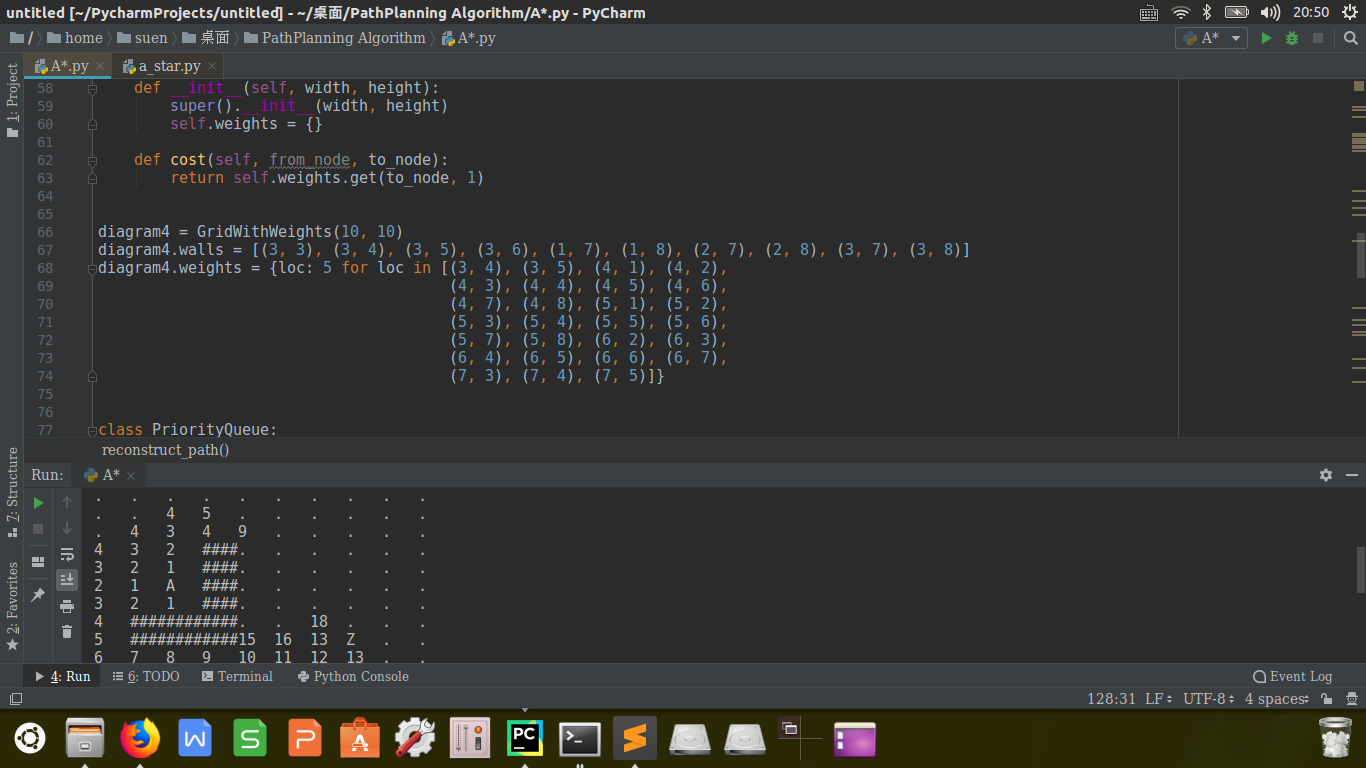
diagram4 = GridWithWeights(10, 10)
diagram4.walls = [(3, 3), (3, 4), (3, 5), (3, 6), (1, 7), (1, 8), (2, 7), (2, 8), (3, 7), (3, 8)]
diagram4.weights = {loc: 5 for loc in [(3, 4), (3, 5), (4, 1), (4, 2),
(4, 3), (4, 4), (4, 5), (4, 6),
(4, 7), (4, 8), (5, 1), (5, 2),
(5, 3), (5, 4), (5, 5), (5, 6),
(5, 7), (5, 8), (6, 2), (6, 3),
(6, 4), (6, 5), (6, 6), (6, 7),
(7, 3), (7, 4), (7, 5)]}
came_from, cost_so_far = a_star_search(diagram4, (2, 5), (7, 8))
优先队列
建立优先队列,利用堆排序的结构保证每次从堆中取出的点是成本值最低的点,代码封装如下:1
2
3
4
5
6
7
8
9
10
11
12class PriorityQueue:
def __init__(self):
self.elements = []
def empty(self):
return len(self.elements) == 0
def put(self, item, priority):
heapq.heappush(self.elements, (priority, item))
def get(self):
return heapq.heappop(self.elements)[1]
距离计算
在我们简化的模型中,H采用的是传统的曼哈顿距离(Manhattan Distance),也就是横纵向走的距离之和。代码封装如下:1
2
3
4
5
6def heuristic(a, b):
(x1, y1) = a
(x2, y2) = b
dx = abs(x1 - x2)
dy = abs(y1 - y2)
return (dx + dy)
路径选取
建立frontier列表用于存放已经遍历过的节点,建立came_from列表用于回溯我们的最终路径,建立cost_so_far列表用于存储节点对应的成本值。对四邻域内的节点进行遍历,对节点对应的新的成本值与最小成本进行比较,若新的成本值小于最小成本,则对cost_so_far列表以及came_from列表进行更新。以此类推进行遍历,直到遍历到目标点为止。代码封装如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def a_star_search(graph, start, goal):
frontier = PriorityQueue()
frontier.put(start, 0)
came_from = {}
cost_so_far = {}
came_from[start] = None
cost_so_far[start] = 0
while not frontier.empty():
current = frontier.get()
if current == goal:
break
for next in graph.neighbors(current):
new_cost = cost_so_far[current] + graph.cost(current, next)
if next not in cost_so_far or new_cost < cost_so_far[next]:
cost_so_far[next] = new_cost
priority = new_cost + heuristic(next,goal)
frontier.put(next, priority)
came_from[next] = current
return came_from, cost_so_far
Heuristic函数
启发式函数h(n)告诉A*从任何结点n到目标结点的最小代价评估值。可以用来控制算法的行为,因此选择一个好的启发式函数很重要。
- h(n)=零。则只有g(n)起作用,此时A*算法演变成Dijkstra算法,能够保证找到最短路径。
- h(n)<实际成本值。那么A* 保证能找到一条最短路径。h(n)越小,需要扩展的点越多,运行速度越慢。
- h(n)=实际成本值。A*将只遵循最佳路径而不会扩展到其他任何结点,能够运行地很快。
- h(n)>实际成本值。则A* 不能保证找到一条最短路径,但它可以运行得更快。
- h(n)远大于g(n)。则只有h(n)起作用,同时A* 算法演变成贪婪最佳优先搜索算法(Greedy Best-First-Search)
由此可见,Heuristic函数影响着最终结果的速度和准确性,至于如何选取就要根据实际需求进行Heuristic函数设计,通过改变遍历节点邻域、改变距离的计算方式(欧式、曼哈顿、对角)、预先计算等不同方法的组合来设计Heuristic函数来满足功能需求。